When building semantic search engines for your cleints, quantization can be confusing. In the end, it’s a simple tradeoff of precision vs speed.
(And all you marketing teams have your own RAG systems integrated into LLMs for you and your clients’ business information, right? …right???)
Why Quantization Is Hard To Understand
The problem is that most explanations of quantization stay abstract.
They talk about lower-precision vectors, reduced memory footprint, and faster similarity search. All of this is true. But unless you already work with embeddings, that doesn’t help much when deciding to implement it or not.
What finally made it click for me was thinking about it like image quality.
Imagine taking an image and reducing it from high color depth down to something much more limited.

At the beginning, with high precision (eg: original vectors), everything looks natural.

Then the image starts looking coarse and unnatural.

Then it starts losing critical details. You can probably guess what’s in the image, but it starts looking pretty far from the original.

Eventually, when you’re down to 1-bit, you have a semi-recognizable image, but a lot less certainty about what’s in that image.

That is quantization.
When You Should (and Should Not) Quantize
So when someone asks me, “Should I quantize my vectors?” the answer is: probably, sometimes, to a point.
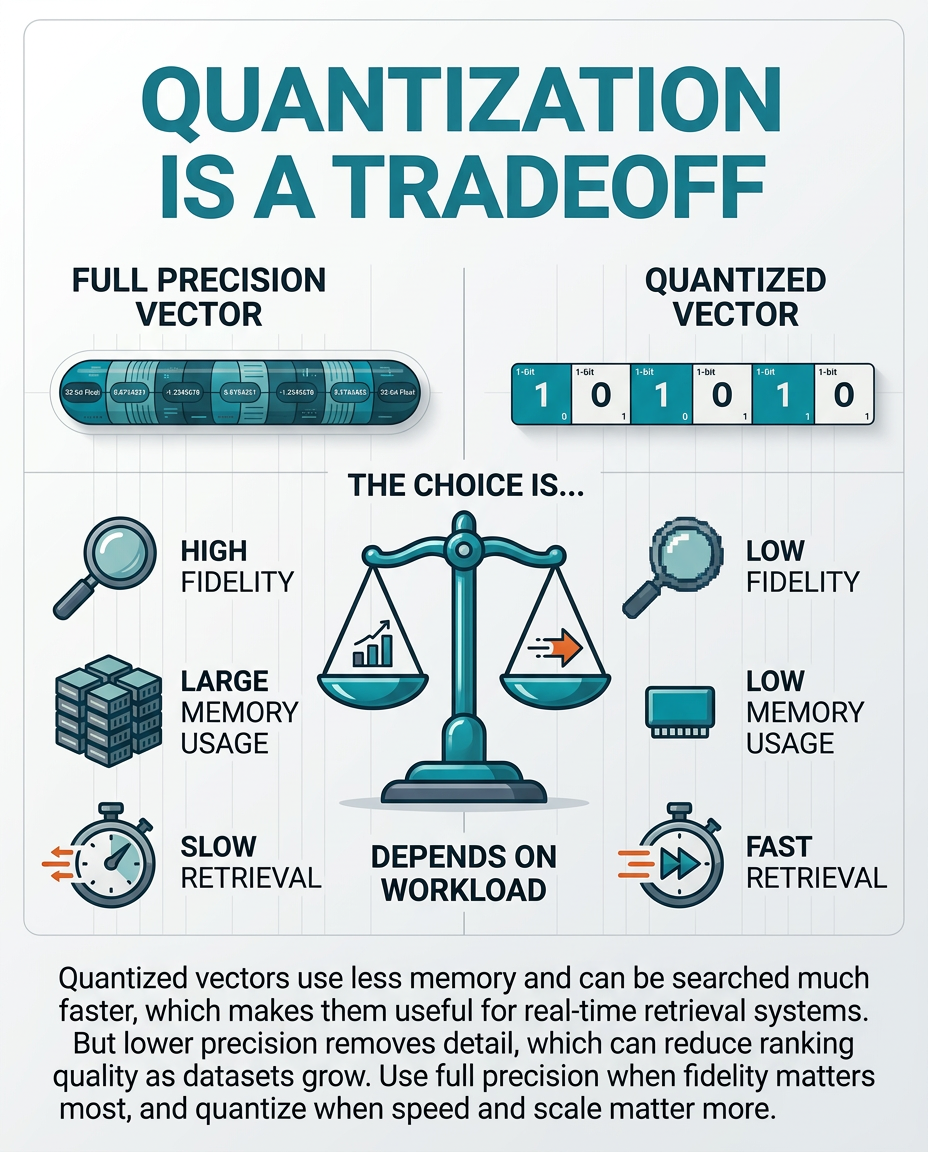
If you have a workload where latency matters, quantization deserves serious consideration. If users are waiting for results, reducing memory pressure and improving speed can be worth a lot.
If you are running jobs overnight, though, and nobody is sitting there waiting on a response, the argument for full precision gets much stronger. In that case, why throw away detail if you do not need to?
Scale matters too.
If your dataset is relatively small, you can often get away with more aggressive quantization because there are fewer near-matches competing with each other. But as your corpus grows, precision starts mattering more. You need higher fidelity to reduce collisions, preserve ranking quality, and separate genuinely relevant results from merely similar ones.
Keep Your Original Vectors
Remember: your quantized vectors don’t usually replace your original vectors.
You still keep the higher-precision source representation. Then you decide whether a lower-precision version is worth using for a specific workload.
The Real Tradeoff
Quantization is not “better” or “worse.” It’s lossy compression.
It is a speed-for-precision tradeoff.
And once you can see that tradeoff, it gets much easier to make the right decision.
Work With Me
Contact me if you want to talk more about this and if I can help your team improve their marketing engineering systems.